


في هدوءٍ لافت، طرحت شركة DeepSeek نموذجها الجديد R1–0528 دون أي ضجة تسويقية تُذكر. ورغم هذا الظهور الصامت، تمكّن النموذج من أسر انتباه مجتمع الذكاء الاصطناعي في غضون ساعات من رفعه على منصة Hugging Face، بفضل قدراته التي تضعه على قدم المُساواة مع نماذج رائدة من OpenAI.
R1–0528: تصميم ذكي بأداء فعال
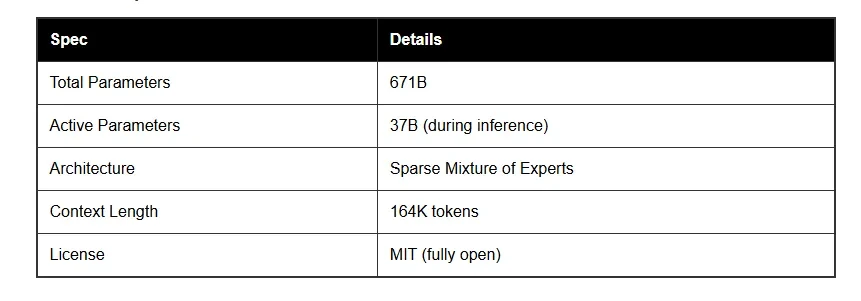
يعتمد R1–0528 على مِعمارية Mixture of Experts (MoE)، وهو ما يُتيح له الجمع بين القوة والاقتصاد في استخدام الموارد. ورغم أنه يحتوي على 671 مليار معلمة، لا تُفعّل سوى 37 مليار معلمة أثناء الاستدلال.
هذا النهج يُقلّل من استهلاك الطاقة الحسابية، ويوفر أداءً مُقاربًا للنماذج فائقة الحجم، ما يجعله مُلائمًا لمن يبحث عن كفاءة تشغيلية دون التضحية بالجودة.
DeepSeek R1–0528: أداء تنافسي في الاختبارات
حقّق النموذج نتائج مُبهرة في اختبارات MMLU، ليقف جنبًا إلى جنب مع GPT-4o-mini وGPT-3.5. وفي اختبار LiveCodeBench لتوليد الأكواد، أثبت R1–0528 كفاءته العالية، مُتفوقًا على نماذج عديدة، وقريبًا جدًا من أداء النماذج الاحتكارية المُخصصّة للبرمجة من OpenAI.
ما يميز هذا النموذج حقًا هو فعاليته في الاستخدامات اليومية والمُعقدّة في نفس الوقت، ومنها:
- الاستدلال الرياضي والمنطقي: حلول دقيقة للمسائل الحسابية مُتعددة الخطوات، مع استيعاب للتفاصيل الرقمية وتسلسل منطقي واضح.
- توليد الأكواد وتطوير المواقع: إنتاج أكواد واضحة وعملية لتطبيقات ومواقع ويب تفاعلية، مع دعم مُتقدم للتقنيات الحديثة مثل SaaS، والرسوم المُتحركة.
- حل المُشكلات والاستنتاج المنطقي: قدرة على تحليل الأسئلة المُعقدّة وتقديم إجابات تستند إلى استدلال منطقي، بل ويمكنه مُعالجة سيناريوهات “ما كان سيحدث لو…” عبر التفكير المُغاير للواقع.
- جودة المُخرجات وسرعة الاستجابة: رغم أن الإجابات العميقة قد تستغرق بعض الوقت، إلا أنّ النتيجة تكون دقيقة، غنية، وذات فهم عميق للسياق، خاصةً مع دعمه لنافذة سياق ضخمة تصل إلى 164 ألف رمز.
خيارات استخدام مرنة
يُتيح DeepSeek الوصول إلى R1–0528 بطرق مُتنوعة تُناسب مُختلف الاحتياجات:
- مجاني عبر OpenRouter: لتجربة النموذج بسهولة من خلال واجهة برمجة التطبيقات دون أي تكلفة.
- API مدفوعة بأسعار تنافسية: 1.95 دولار لكل مليون رمز إدخال، و5 دولارات لكل مليون رمز إخراج.
- تشغيل محلي مُخفّض الحجم: ضغطّت DeepSeek حجم النموذج من 720 إلى 131 جيجابايت ليكون قابلًا للتشغيل على أجهزة شخصية قوية دون الحاجة لخوادم (سيرفرات) سحابية.
- دردشة تفاعلية عبر منصة DeepSeek: إمكانية استخدام النموذج مُباشرةً مع تفعيل وضع التفكير العميق “Deep Think” لمهام تحليلية أكثر تقدمًا.

لماذا R1–0528 مُهمًا؟
- ترخيص MIT مفتوح المصدر: حرية كاملة في التعديل والتوزيع والاستخدام.
- شفافية كاملة: يمكن للباحثين فحص طريقة عمل النموذج داخليًا وتحليل قراراته.
- مُنافس حقيقي للنماذج الاحتكارية: يُقدّم أداءً قويًا يجعل الذكاء الاصطناعي المُتقدّم مُتاحًا للجميع، بعيدًا عن قيود الشركات الكبرى.
نموذج R1–0528 ليس مُجرّد تجربة بحثية، بل هو حجر أساس في طريق الذكاء الاصطناعي المفتوح المصدر. بفضل أدائه المُتقدّم، ومُرونته المُرتفعة، وشفافيته الكاملة، يُمثّل خيارًا مِثاليًا للباحثين، المُطورين، والشركات التي تبحث عن قوة الذكاء الاصطناعي دون قيود الملكية.
يمكنك البدء بتجربته الآن عبر Hugging Face أو OpenRouter، أو حتى تشغيله على جهازك إن كنت تملك الهاردوير المُناسب.
?xml>
