


مع شدّة السباق العالمي لتطوير نماذج الذكاء الاصطناعي المتقدمة، تواجه شركة ميتا تحديات كبيرة تعكس تعقيدات المُنافسة في هذا المجال الحيوي. بين تأجيل إطلاق أضخم نماذج Llama 4 -بيهيموث “Behemoth”- وانتقادات حول تراجُّع أداء عائلة نماذج “لاما” المفتوحة المصدر، تظهر تساؤلات حول قدرة الشركة على الحفاظ على ريادتها في هذا القطاع سريع التطور.
اقرأ أيضًا:
ميتا تطلق Llama 4 : قوة جديدة في عصر الذكاء الاصطناعي
كيف ترى ميتا مستقبل التكنولوجيا بعين ثالثة؟
تأجيل Behemoth: مُعضلة تقنية وإدارية
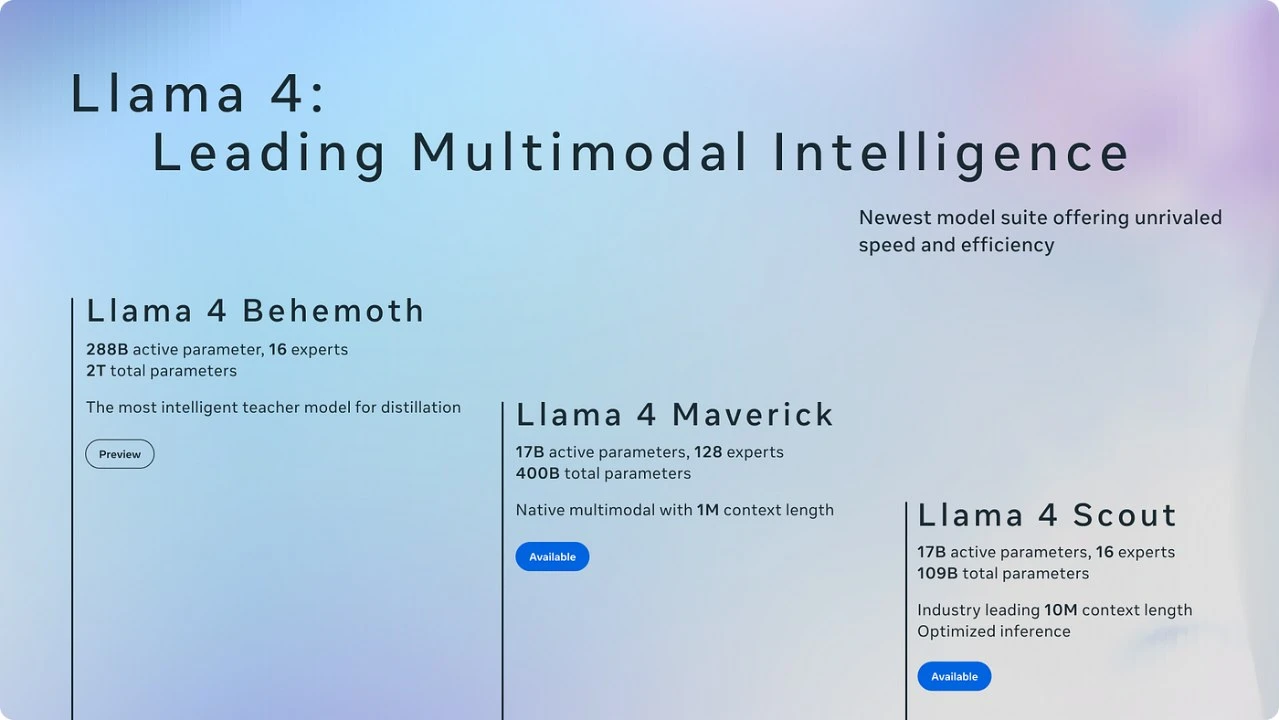
أجلّت ميتا إطلاق نموذجها العملاق “بيهيموث” للذكاء الاصطناعي مرات مُتتالية، من أبريل إلى يونيو ثم إلى الخريف، وسط صعوبات تقنية في تحسين أدائه. وفقًا لمصادر داخلية، يعاني المهندسون من تحديات في جعل النموذج قادرًا على مُجاراة التصريحات العلنية لميتا حول تفوقه على مُنافسيه مثل GPT-4 من OpenAI وClaude من Anthropic.
القلق الداخلي لا يقتصر على الجانب التقني؛ فكبار المديرين التنفيذيين يُظهرون إحباطًا من أداء الفريق المسؤول عن تطوير Llama 4، وهو ما دفع الشركة إلى النظر في إعادة هيكلة إدارية لفريق الذكاء الاصطناعي.
يُذكر أن ميتا أنفقت مليارات الدولارات على البنية التحتية الحاسوبية لدعم طموحاتها، مع خطة إنفاق رأسمالي تصل إلى 72 مليار دولار في 2025، جزء كبير منها مُوجه لتطوير الذكاء الاصطناعي.
“لاما” تفقد بريقها: انتكاسة في المصدر المفتوح

كانت نماذج “لاما” المفتوحة المصدر تُعتبر إنجازًا بارزًا لميتا، حيث أشاد بها خبراء مثل جينسن هوانغ -الرئيس التنفيذي لإنفيديا- وصف إطلاق Llama 2 بأنه “أكبر حدث في مجال الذكاء الاصطناعي” عام 2023. لكن الصورة اختلفت مع الجيل الرابع Llama 4.
في مؤتمر LlamaCon الأول للشركة، عبّر المُطورون عن خيبة أملهم لعدم إعلان ميتا عن نموذج استدلالي قوي يتفوق على منافسين مثل “DeepSeek V3” أو “Qwen” من علي بابا. وعلى الرغم من إطلاق نموذجَيّ Scout وMaverick ضمن عائلة Llama 4، إلا أنّ الأداء الفعلي للنماذج المُتاحة للجمهور لم يرقَ إلى المُستوى المُعلن في الاختبارات المعيارية، وهذا أثار اتهامات بالتلاعب بقوائم التصنيف.
فجوة الأداء: بين الادعاءات والواقع
أظهرت بيانات منصات مثل Artificial Analysis وOpenRouter أنّ نماذج ميتا الأخيرة ليست في صدارة التصنيفات. ففي حين ادعت الشركة أن Maverick يتفوق على GPT-4، احتلّ نموذج Qwen الصيني الصدارة في قوائم الأداء، بينما لم يظهر Llama 4 ضمن أفضل 20 نموذجًا على “OpenRouter”.
الانتقادات لم تتوقف عند ذلك؛ فقد كشفت تحقيقات أنّ النموذج الذي اختبرته ميتا في القوائم المعيارية كان نسخة مُخصصة مُحسنة، وليس الإصدار المُتاح للجمهور. واعترف مارك زوكربيرج بنفسه بأن الشركة قدّمت نسخة مُعدّلة لتحقيق نتائج أفضل، ممّا أضر بمِصداقية ادعاءات الشركة.
مُستقبل الذكاء الاصطناعي في ميتا: هل تستعيد قوتها؟

تواجه ميتا مُفترق طرق: من ناحية، تحتاج إلى تسريع تطوير نماذجها لتعويض التأخير، ومن ناحيةٍ أخرى، عليها استعادة ثقة المُطورين بعد تراجع تأثير Llama. بعض الخبراء، مثل رافيد شوارتز-زيف من جامعة نيويورك، يرون أن التقدُّم في مجال النماذج الكبيرة أصبح أبطأ وأكثر تكلفةً، وذلك قد يعطي ميتا فرصة لإعادة تنظيم استراتيجيتها.
تعتمد الشركة حاليًا على خيارين: إمّا إطلاق نسخة محدودة من Behemoth بشكل عاجل، أو الاستثمار في تحسين البنية التحتية مثل تقنية “مزيج الخبراء” التي ترفع كفاءة النماذج.
لكن التحدّي الأكبر يبقى في كيفية مواكبة تطورات مُنافسين مثل Anthropic التي تستعد لإطلاق Claude 3.5 Opus، وOpenAI التي تعمل على GPT-5.
بينما تُظهر ميتا التزامًا استثماريًا غير مسبوق في الذكاء الاصطناعي، فإن التحديات التقنية والإدارية وتزايُّد المُنافسة تضعها تحت مِجهر النقد. نجاحها المُستقبلي قد يعتمد ليس فقط على حل إشكالات النماذج الحالية، بل أيضًا على قدرتها على إعادة ابتكار سردية تُعيد جذب المجتمع التقني والمُطورين، الذين بدأوا يتطلعون إلى بدائل أكثر فعاليةً في سوقٍ لم يعد الصبر من فضائله!
?xml>
